
2026 |
|
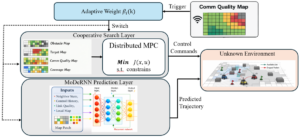 | Hybrid Framework for Multi-Robot Target Search in Unknown and Adversarial Environments Conference Forthcoming 2026 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Forthcoming. Abstract | Links | BibTeX | Tags: cooperation, learning, localization, multi-robot systems @conference{Tasooji2026c, title = {Hybrid Framework for Multi-Robot Target Search in Unknown and Adversarial Environments}, author = {Tohid Kargar Tasooji and Ramviyas Parasuraman}, url = {https://herolab.org/tasooji_iros_2026_hdmpc/}, year = {2026}, date = {2026-09-27}, booktitle = {2026 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, abstract = {This paper presents a hybrid framework for multi-robot multi-target search in unknown, cluttered, and adversarial environments with limited sensing and intermittent communication. We employ a unified grid-based map encoding obstacles, coverage, target likelihood, and communication quality, together with a probabilistic adversarial model using layered Gaussian-like danger zones to capture the impact of varying adversary levels. On top of this representation, we develop an adaptive communication-aware, learning-based distributed MPC scheme that uses shared maps for cooperative trajectory planning under strong communication and learned inter-robot interaction models to predict neighbor states and maintain search efficiency when communication degrades, thereby reducing reliance on real-time data exchange. Extensive experiments on diverse maps with static and dynamic targets show that the proposed method reduces communication overhead and search time while improving prediction accuracy and overall resilience across different levels of adversaries. }, keywords = {cooperation, learning, localization, multi-robot systems}, pubstate = {forthcoming}, tppubtype = {conference} } This paper presents a hybrid framework for multi-robot multi-target search in unknown, cluttered, and adversarial environments with limited sensing and intermittent communication. We employ a unified grid-based map encoding obstacles, coverage, target likelihood, and communication quality, together with a probabilistic adversarial model using layered Gaussian-like danger zones to capture the impact of varying adversary levels. On top of this representation, we develop an adaptive communication-aware, learning-based distributed MPC scheme that uses shared maps for cooperative trajectory planning under strong communication and learned inter-robot interaction models to predict neighbor states and maintain search efficiency when communication degrades, thereby reducing reliance on real-time data exchange. Extensive experiments on diverse maps with static and dynamic targets show that the proposed method reduces communication overhead and search time while improving prediction accuracy and overall resilience across different levels of adversaries. |
 | Imitation-BT: Automating Behavior Tree Generation by Echoing Reinforcement Learning Agents Conference 2026 IEEE International Conference on Robotics & Automation (ICRA), 2026. Abstract | Links | BibTeX | Tags: autonomy, behavior-trees, learning, planning @conference{Bthula2026, title = {Imitation-BT: Automating Behavior Tree Generation by Echoing Reinforcement Learning Agents}, author = {Shailendra Sekhar Bthula and Ramviyas Parasuraman}, url = {https://herolab.org/bathula___icra_2026___imitationbt__behavior_trees_learned_from_rl_models_v2/}, year = {2026}, date = {2026-06-01}, booktitle = {2026 IEEE International Conference on Robotics & Automation (ICRA)}, abstract = {Understanding an autonomous agent's decision-making prowess is of paramount importance, as it increases trust and guarantees safety. Although agent policies learned through reinforcement learning (RL) and machine learning (ML) paradigms have demonstrated their dominance in various domains, they struggle with deployment in high-stakes environments due to their algorithmic opacity. A structured and transparent representation of a policy helps us understand, evaluate, and modify it if necessary. Due to their inherent reactivity, modularity, and transparent hierarchical representation, the Behavior Tree (BT) is an ideal solution to represent control policies. In this paper, we focus on building a knowledge representation transfer framework in which knowledge of trained RL agents is captured through imitation learning and then utilized to form a compact BT. Our primary focus is to retain maximum performance while improving the interpretability of the BTs. In combination with planning and learning, we automate the formation of a BT and offer an alternative, transparent architecture for policy representation. In an extensive analysis with a variety of gymnasium environments and the Robotics Package Delivery domain simulations, we demonstrate the significant performance retention capability and superior interpretability of the proposed Imitation-BT. }, keywords = {autonomy, behavior-trees, learning, planning}, pubstate = {published}, tppubtype = {conference} } Understanding an autonomous agent's decision-making prowess is of paramount importance, as it increases trust and guarantees safety. Although agent policies learned through reinforcement learning (RL) and machine learning (ML) paradigms have demonstrated their dominance in various domains, they struggle with deployment in high-stakes environments due to their algorithmic opacity. A structured and transparent representation of a policy helps us understand, evaluate, and modify it if necessary. Due to their inherent reactivity, modularity, and transparent hierarchical representation, the Behavior Tree (BT) is an ideal solution to represent control policies. In this paper, we focus on building a knowledge representation transfer framework in which knowledge of trained RL agents is captured through imitation learning and then utilized to form a compact BT. Our primary focus is to retain maximum performance while improving the interpretability of the BTs. In combination with planning and learning, we automate the formation of a BT and offer an alternative, transparent architecture for policy representation. In an extensive analysis with a variety of gymnasium environments and the Robotics Package Delivery domain simulations, we demonstrate the significant performance retention capability and superior interpretability of the proposed Imitation-BT. |
2025 |
|
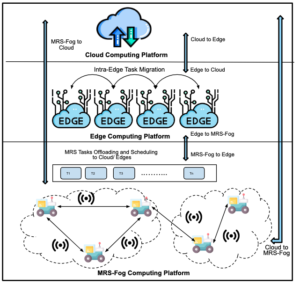 | Edge Computing and its Application in Robotics: A Survey Journal Article Journal of Sensor and Actuator Networks, 14 (4), 2025. Abstract | Links | BibTeX | Tags: computing, learning, multi-robot systems, networking @article{Tahir2025, title = {Edge Computing and its Application in Robotics: A Survey}, author = {Nazish Tahir and Ramviyas Parasuraman}, url = {https://www.mdpi.com/2224-2708/14/4/65}, doi = {10.3390/jsan14040065}, year = {2025}, date = {2025-06-23}, journal = {Journal of Sensor and Actuator Networks}, volume = {14}, number = {4}, abstract = {The edge computing paradigm has gained prominence in both academic and industry circles in recent years. When edge computing facilities and services are implemented in robotics, they become a key enabler in the deployment of artificial intelligence applications to robots. Time-sensitive robotics applications benefit from the reduced latency, mobility, and location awareness provided by the edge computing paradigm, which enables real-time data processing and intelligence at the network’s edge. While the advantages of integrating edge computing into robotics are numerous, there has been no recent survey that comprehensively examines these benefits. This paper aims to bridge that gap by highlighting important work in the domain of edge robotics, examining recent advancements, and offering deeper insight into the challenges and motivations behind both current and emerging solutions. In particular, this article provides a comprehensive evaluation of recent developments in edge robotics, with an emphasis on fundamental applications, providing in-depth analysis of the key motivations, challenges, and future directions in this rapidly evolving domain. It also explores the importance of edge computing in real-world robotics scenarios where rapid response times are critical. Finally, the paper outlines various open research challenges in the field of edge robotics. }, keywords = {computing, learning, multi-robot systems, networking}, pubstate = {published}, tppubtype = {article} } The edge computing paradigm has gained prominence in both academic and industry circles in recent years. When edge computing facilities and services are implemented in robotics, they become a key enabler in the deployment of artificial intelligence applications to robots. Time-sensitive robotics applications benefit from the reduced latency, mobility, and location awareness provided by the edge computing paradigm, which enables real-time data processing and intelligence at the network’s edge. While the advantages of integrating edge computing into robotics are numerous, there has been no recent survey that comprehensively examines these benefits. This paper aims to bridge that gap by highlighting important work in the domain of edge robotics, examining recent advancements, and offering deeper insight into the challenges and motivations behind both current and emerging solutions. In particular, this article provides a comprehensive evaluation of recent developments in edge robotics, with an emphasis on fundamental applications, providing in-depth analysis of the key motivations, challenges, and future directions in this rapidly evolving domain. It also explores the importance of edge computing in real-world robotics scenarios where rapid response times are critical. Finally, the paper outlines various open research challenges in the field of edge robotics. |
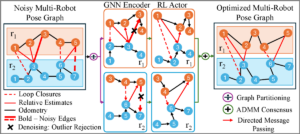 | 2025 IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS), 2025. Abstract | Links | BibTeX | Tags: learning, localization, mapping, multi-robot systems, perception @conference{Ghanta2025c, title = {Policies over Poses: Reinforcement Learning based Distributed Pose-Graph Optimization for Multi-Robot SLAM}, author = {Sai Krishna Ghanta and Ramviyas Parasuraman}, url = {https://ieeexplore.ieee.org/document/11357260}, doi = {10.1109/MRS66243.2025.11357260}, year = {2025}, date = {2025-12-04}, booktitle = {2025 IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS)}, abstract = {We consider the distributed pose-graph optimization (PGO) problem, which is fundamental in accurate trajectory estimation in multi-robot simultaneous localization and mapping (SLAM). Conventional iterative approaches linearize a highly non-convex optimization objective, requiring repeated solving of normal equations, which often converge to local minima and thus produce suboptimal estimates. We propose a scalable, outlier-robust distributed planar PGO framework using Multi-Agent Reinforcement Learning (MARL). We cast distributed PGO as a partially observable Markov game defined on local pose-graphs, where each action refines a single edge's pose estimate. A graph partitioner decomposes the global pose graph, and each robot runs a recurrent edge-conditioned Graph Neural Network (GNN) encoder with adaptive edge-gating to denoise noisy edges. Robots sequentially refine poses through a hybrid policy that utilizes prior action memory and graph embeddings. After local graph correction, a consensus scheme reconciles inter-robot disagreements to produce a globally consistent estimate. Our extensive evaluations on a comprehensive suite of synthetic and real-world datasets demonstrate that our learned MARL-based actors reduce the global objective by an average of 37.5% more than the state-of-the-art distributed PGO framework, while enhancing inference efficiency by at least 6X. We also demonstrate that actor replication allows a single learned policy to scale effortlessly to substantially larger robot teams without any retraining. Code is publicly available at https://github.com/herolab-uga/policies-over-poses }, keywords = {learning, localization, mapping, multi-robot systems, perception}, pubstate = {published}, tppubtype = {conference} } We consider the distributed pose-graph optimization (PGO) problem, which is fundamental in accurate trajectory estimation in multi-robot simultaneous localization and mapping (SLAM). Conventional iterative approaches linearize a highly non-convex optimization objective, requiring repeated solving of normal equations, which often converge to local minima and thus produce suboptimal estimates. We propose a scalable, outlier-robust distributed planar PGO framework using Multi-Agent Reinforcement Learning (MARL). We cast distributed PGO as a partially observable Markov game defined on local pose-graphs, where each action refines a single edge's pose estimate. A graph partitioner decomposes the global pose graph, and each robot runs a recurrent edge-conditioned Graph Neural Network (GNN) encoder with adaptive edge-gating to denoise noisy edges. Robots sequentially refine poses through a hybrid policy that utilizes prior action memory and graph embeddings. After local graph correction, a consensus scheme reconciles inter-robot disagreements to produce a globally consistent estimate. Our extensive evaluations on a comprehensive suite of synthetic and real-world datasets demonstrate that our learned MARL-based actors reduce the global objective by an average of 37.5% more than the state-of-the-art distributed PGO framework, while enhancing inference efficiency by at least 6X. We also demonstrate that actor replication allows a single learned policy to scale effortlessly to substantially larger robot teams without any retraining. Code is publicly available at https://github.com/herolab-uga/policies-over-poses |
2024 |
|
 | Bayesian Strategy Networks Based Soft Actor-Critic Learning Journal Article ACM Transactions on Intelligent Systems and Technology, 15 (3), pp. 1–24, 2024. Abstract | Links | BibTeX | Tags: control, learning @article{Yang2024b, title = {Bayesian Strategy Networks Based Soft Actor-Critic Learning}, author = {Qin Yang and Ramviyas Parasuraman}, url = {https://dl.acm.org/doi/10.1145/3643862}, doi = {10.1145/3643862}, year = {2024}, date = {2024-03-29}, journal = {ACM Transactions on Intelligent Systems and Technology}, volume = {15}, number = {3}, pages = {1–24}, abstract = {A strategy refers to the rules that the agent chooses the available actions to achieve goals. Adopting reasonable strategies is challenging but crucial for an intelligent agent with limited resources working in hazardous, unstructured, and dynamic environments to improve the system’s utility, decrease the overall cost, and increase mission success probability. This paper proposes a novel hierarchical strategy decomposition approach based on Bayesian chaining to separate an intricate policy into several simple sub-policies and organize their relationships as Bayesian strategy networks (BSN). We integrate this approach into the state-of-the-art DRL method – soft actor-critic (SAC), and build the corresponding Bayesian soft actor-critic (BSAC) model by organizing several sub-policies as a joint policy. Our method achieves the state-of-the-art performance on the standard continuous control benchmarks in the OpenAI Gym environment. The results demonstrate that the promising potential of the BSAC method significantly improves training efficiency. Furthermore, we extend the topic to the Multi-Agent systems (MAS), discussing the potential research fields and directions.}, keywords = {control, learning}, pubstate = {published}, tppubtype = {article} } A strategy refers to the rules that the agent chooses the available actions to achieve goals. Adopting reasonable strategies is challenging but crucial for an intelligent agent with limited resources working in hazardous, unstructured, and dynamic environments to improve the system’s utility, decrease the overall cost, and increase mission success probability. This paper proposes a novel hierarchical strategy decomposition approach based on Bayesian chaining to separate an intricate policy into several simple sub-policies and organize their relationships as Bayesian strategy networks (BSN). We integrate this approach into the state-of-the-art DRL method – soft actor-critic (SAC), and build the corresponding Bayesian soft actor-critic (BSAC) model by organizing several sub-policies as a joint policy. Our method achieves the state-of-the-art performance on the standard continuous control benchmarks in the OpenAI Gym environment. The results demonstrate that the promising potential of the BSAC method significantly improves training efficiency. Furthermore, we extend the topic to the Multi-Agent systems (MAS), discussing the potential research fields and directions. |
 | Communication-Efficient Multi-Robot Exploration Using Coverage-biased Distributed Q-Learning Journal Article IEEE Robotics and Automation Letters, 9 (3), pp. 2622 - 2629, 2024. Abstract | Links | BibTeX | Tags: cooperation, learning, mapping, multi-robot, networking @article{Latif2024b, title = {Communication-Efficient Multi-Robot Exploration Using Coverage-biased Distributed Q-Learning}, author = {Ehsan Latif and Ramviyas Parasuraman}, url = {https://ieeexplore.ieee.org/document/10413563}, doi = {10.1109/LRA.2024.3358095}, year = {2024}, date = {2024-03-01}, journal = {IEEE Robotics and Automation Letters}, volume = {9}, number = {3}, pages = {2622 - 2629}, abstract = {Frontier exploration and reinforcement learning have historically been used to solve the problem of enabling many mobile robots to autonomously and cooperatively explore complex surroundings. These methods need to keep an internal global map for navigation, but they do not take into consideration the high costs of communication and information sharing between robots. This study offers CQLite, a novel distributed Q-learning technique designed to minimize data communication overhead between robots while achieving rapid convergence and thorough coverage in multi-robot exploration. The proposed CQLite method uses ad hoc map merging, and selectively shares updated Q-values at recently identified frontiers to significantly reduce communication costs. The theoretical analysis of CQLite's convergence and efficiency, together with extensive numerical verification on simulated indoor maps utilizing several robots, demonstrates the method's novelty. With over 2x reductions in computation and communication alongside improved mapping performance, CQLite outperformed cutting-edge multi-robot exploration techniques like Rapidly Exploring Random Trees and Deep Reinforcement Learning. }, keywords = {cooperation, learning, mapping, multi-robot, networking}, pubstate = {published}, tppubtype = {article} } Frontier exploration and reinforcement learning have historically been used to solve the problem of enabling many mobile robots to autonomously and cooperatively explore complex surroundings. These methods need to keep an internal global map for navigation, but they do not take into consideration the high costs of communication and information sharing between robots. This study offers CQLite, a novel distributed Q-learning technique designed to minimize data communication overhead between robots while achieving rapid convergence and thorough coverage in multi-robot exploration. The proposed CQLite method uses ad hoc map merging, and selectively shares updated Q-values at recently identified frontiers to significantly reduce communication costs. The theoretical analysis of CQLite's convergence and efficiency, together with extensive numerical verification on simulated indoor maps utilizing several robots, demonstrates the method's novelty. With over 2x reductions in computation and communication alongside improved mapping performance, CQLite outperformed cutting-edge multi-robot exploration techniques like Rapidly Exploring Random Trees and Deep Reinforcement Learning. |
 | 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024), 2024. Abstract | Links | BibTeX | Tags: learning, mapping, perception @conference{Ravipati2024, title = {Object-Oriented Material Classification and 3D Clustering for Improved Semantic Perception and Mapping in Mobile Robots}, author = {Siva Krishna Ravipati and Ehsan Latif and Suchendra Bhandarkar and Ramviyas Parasuraman }, url = {https://ieeexplore.ieee.org/document/10801936}, doi = {10.1109/IROS58592.2024.10801936}, year = {2024}, date = {2024-10-13}, booktitle = {2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024)}, pages = {9729-9736}, abstract = {Classification of different object surface material types can play a significant role in the decision-making algorithms for mobile robots and autonomous vehicles. RGB-based scene-level semantic segmentation has been well-addressed in the literature. However, improving material recognition using the depth modality and its integration with SLAM algorithms for 3D semantic mapping could unlock new potential benefits in the robotics perception pipeline. To this end, we propose a complementarity-aware deep learning approach for RGB-D-based material classification built on top of an object-oriented pipeline. The approach further integrates the ORB-SLAM2 method for 3D scene mapping with multiscale clustering of the detected material semantics in the point cloud map generated by the visual SLAM algorithm. Extensive experimental results with existing public datasets and newly contributed real-world robot datasets demonstrate a significant improvement in material classification and 3D clustering accuracy compared to state-of-the-art approaches for 3D semantic scene mapping. }, keywords = {learning, mapping, perception}, pubstate = {published}, tppubtype = {conference} } Classification of different object surface material types can play a significant role in the decision-making algorithms for mobile robots and autonomous vehicles. RGB-based scene-level semantic segmentation has been well-addressed in the literature. However, improving material recognition using the depth modality and its integration with SLAM algorithms for 3D semantic mapping could unlock new potential benefits in the robotics perception pipeline. To this end, we propose a complementarity-aware deep learning approach for RGB-D-based material classification built on top of an object-oriented pipeline. The approach further integrates the ORB-SLAM2 method for 3D scene mapping with multiscale clustering of the detected material semantics in the point cloud map generated by the visual SLAM algorithm. Extensive experimental results with existing public datasets and newly contributed real-world robot datasets demonstrate a significant improvement in material classification and 3D clustering accuracy compared to state-of-the-art approaches for 3D semantic scene mapping. |
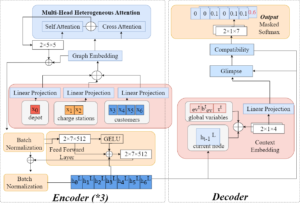 | Route Planning for Electric Vehicles with Charging Constraints Conference 2024 IEEE 100th Vehicular Technology Conference (VTC2024-Fall), 2024. Abstract | Links | BibTeX | Tags: control, learning, multi-robot systems @conference{Munir2024c, title = {Route Planning for Electric Vehicles with Charging Constraints}, author = {Aiman Munir, Ramviyas Parasuraman, Jin Ye, WenZhan Song}, url = {https://ieeexplore.ieee.org/abstract/document/10757558}, doi = {10.1109/VTC2024-Fall63153.2024.10757558}, year = {2024}, date = {2024-10-10}, booktitle = {2024 IEEE 100th Vehicular Technology Conference (VTC2024-Fall)}, pages = {2577-2465}, abstract = {Recent studies demonstrate the efficacy of machine learning algorithms for learning strategies to solve combinatorial optimization problems. This study presents a novel solution to address the Electric Vehicle Routing Problem with Time Windows (EVRPTW), leveraging deep reinforcement learning (DRL) techniques. Existing DRL approaches frequently encounter challenges when addressing the EVRPTW problem: RNN-based decoders struggle with capturing long-term dependencies, while DDQN models exhibit limited generalization across various problem sizes. To overcome these limitations, we introduce a transformer-based model with a heterogeneous attention mechanism. Transformers excel at capturing long-term dependencies and demonstrate superior generalization across diverse problem instances. We validate the efficacy of our proposed approach through comparative analysis against two state-of-the-art solutions for EVRPTW. The results demonstrated the efficacy of the proposed model in minimizing the distance traveled and robust generalization across varying problem sizes. }, keywords = {control, learning, multi-robot systems}, pubstate = {published}, tppubtype = {conference} } Recent studies demonstrate the efficacy of machine learning algorithms for learning strategies to solve combinatorial optimization problems. This study presents a novel solution to address the Electric Vehicle Routing Problem with Time Windows (EVRPTW), leveraging deep reinforcement learning (DRL) techniques. Existing DRL approaches frequently encounter challenges when addressing the EVRPTW problem: RNN-based decoders struggle with capturing long-term dependencies, while DDQN models exhibit limited generalization across various problem sizes. To overcome these limitations, we introduce a transformer-based model with a heterogeneous attention mechanism. Transformers excel at capturing long-term dependencies and demonstrate superior generalization across diverse problem instances. We validate the efficacy of our proposed approach through comparative analysis against two state-of-the-art solutions for EVRPTW. The results demonstrated the efficacy of the proposed model in minimizing the distance traveled and robust generalization across varying problem sizes. |
 | Bayesian Soft Actor-Critic: A Directed Acyclic Strategy Graph Based Deep Reinforcement Learning Conference 2024 ACM/SIGAPP Symposium on Applied Computing (SAC) , IRMAS Track 2024. Abstract | Links | BibTeX | Tags: control, learning @conference{Yang2024, title = {Bayesian Soft Actor-Critic: A Directed Acyclic Strategy Graph Based Deep Reinforcement Learning}, author = {Qin Yang and Ramviyas Parasuraman}, url = {https://dl.acm.org/doi/10.1145/3605098.3636113}, doi = {10.1145/3605098.3636113}, year = {2024}, date = {2024-04-08}, booktitle = {2024 ACM/SIGAPP Symposium on Applied Computing (SAC) }, series = {IRMAS Track}, abstract = {Adopting reasonable strategies is challenging but crucial for an intelligent agent with limited resources working in hazardous, unstructured, and dynamic environments to improve the system's utility, decrease the overall cost, and increase mission success probability. This paper proposes a novel directed acyclic strategy graph decomposition approach based on Bayesian chaining to separate an intricate policy into several simple sub-policies and organize their relationships as Bayesian strategy networks (BSN). We integrate this approach into the state-of-the-art DRL method -- soft actor-critic (SAC), and build the corresponding Bayesian soft actor-critic (BSAC) model by organizing several sub-policies as a joint policy. We compare our method against the state-of-the-art deep reinforcement learning algorithms on the standard continuous control benchmarks in the OpenAI Gym environment. The results demonstrate that the promising potential of the BSAC method significantly improves training efficiency. }, keywords = {control, learning}, pubstate = {published}, tppubtype = {conference} } Adopting reasonable strategies is challenging but crucial for an intelligent agent with limited resources working in hazardous, unstructured, and dynamic environments to improve the system's utility, decrease the overall cost, and increase mission success probability. This paper proposes a novel directed acyclic strategy graph decomposition approach based on Bayesian chaining to separate an intricate policy into several simple sub-policies and organize their relationships as Bayesian strategy networks (BSN). We integrate this approach into the state-of-the-art DRL method -- soft actor-critic (SAC), and build the corresponding Bayesian soft actor-critic (BSAC) model by organizing several sub-policies as a joint policy. We compare our method against the state-of-the-art deep reinforcement learning algorithms on the standard continuous control benchmarks in the OpenAI Gym environment. The results demonstrate that the promising potential of the BSAC method significantly improves training efficiency. |
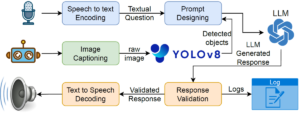 | PhysicsAssistant: An LLM-Powered Interactive Learning Robot for Physics Lab Investigations Workshop IEEE ICRA 2024 Workshop on Accelerating Discovery in Natural Science Laboratories with AI and Robotics, 2024, (Selected for the Pioneer Award). Abstract | Links | BibTeX | Tags: assistive devices, autonomy, human-robot interaction, human-robot interface, learning @workshop{Latif2024d, title = {PhysicsAssistant: An LLM-Powered Interactive Learning Robot for Physics Lab Investigations}, author = {Ehsan Latif, Ramviyas Parasuraman, and Xiaoming Zhai}, url = {https://sites.google.com/view/icra24-accelerating-discovery}, year = {2024}, date = {2024-05-13}, booktitle = {IEEE ICRA 2024 Workshop on Accelerating Discovery in Natural Science Laboratories with AI and Robotics}, abstract = {Robot systems in education can leverage Large language models' (LLMs) natural language understanding capabilities to provide assistance and facilitate learning. This paper proposes a multimodal interactive robot (PhysicsAssistant) built on YOLOv8 object detection, cameras, speech recognition, and chatbot using LLM to provide assistance to students' physics labs. We conduct a user study on ten 8th-grade students to empirically evaluate the performance of PhysicsAssistant with a human expert. The Expert rates the assistants' responses to student queries on a 0-4 scale based on Bloom's taxonomy to provide educational support. We have compared the performance of PhysicsAssistant (YOLOv8+GPT-3.5-turbo) with GPT-4 and found that the human expert rating of both systems for factual understanding is same. However, the rating of GPT-4 for conceptual and procedural knowledge (3 and 3.2 vs 2.2 and 2.6, respectively) is significantly higher than PhysicsAssistant (p $<$ 0.05). However, the response time of GPT-4 is significantly higher than PhysicsAssistant (3.54 vs 1.64 sec, p $<$ 0.05). Hence, despite the relatively lower response quality of PhysicsAssistant than GPT-4, it has shown potential for being used as a real-time lab assistant to provide timely responses and can offload teachers' labor to assist with repetitive tasks. To the best of our knowledge, this is the first attempt to build such an interactive multimodal robotic assistant for K-12 science (physics) education. }, note = {Selected for the Pioneer Award}, keywords = {assistive devices, autonomy, human-robot interaction, human-robot interface, learning}, pubstate = {published}, tppubtype = {workshop} } Robot systems in education can leverage Large language models' (LLMs) natural language understanding capabilities to provide assistance and facilitate learning. This paper proposes a multimodal interactive robot (PhysicsAssistant) built on YOLOv8 object detection, cameras, speech recognition, and chatbot using LLM to provide assistance to students' physics labs. We conduct a user study on ten 8th-grade students to empirically evaluate the performance of PhysicsAssistant with a human expert. The Expert rates the assistants' responses to student queries on a 0-4 scale based on Bloom's taxonomy to provide educational support. We have compared the performance of PhysicsAssistant (YOLOv8+GPT-3.5-turbo) with GPT-4 and found that the human expert rating of both systems for factual understanding is same. However, the rating of GPT-4 for conceptual and procedural knowledge (3 and 3.2 vs 2.2 and 2.6, respectively) is significantly higher than PhysicsAssistant (p $<$ 0.05). However, the response time of GPT-4 is significantly higher than PhysicsAssistant (3.54 vs 1.64 sec, p $<$ 0.05). Hence, despite the relatively lower response quality of PhysicsAssistant than GPT-4, it has shown potential for being used as a real-time lab assistant to provide timely responses and can offload teachers' labor to assist with repetitive tasks. To the best of our knowledge, this is the first attempt to build such an interactive multimodal robotic assistant for K-12 science (physics) education. |
2023 |
|
 | A Strategy-Oriented Bayesian Soft Actor-Critic Model Conference Procedia Computer Science, 220 , ANT 2023 Elsevier, 2023. Abstract | Links | BibTeX | Tags: autonomy, learning @conference{Yang2023b, title = {A Strategy-Oriented Bayesian Soft Actor-Critic Model}, author = {Qin Yang and Ramviyas Parasuraman}, url = {https://www.sciencedirect.com/science/article/pii/S1877050923006063}, doi = {10.1016/j.procs.2023.03.071}, year = {2023}, date = {2023-03-17}, booktitle = {Procedia Computer Science}, journal = {Procedia Computer Science}, volume = {220}, pages = {561-566}, publisher = {Elsevier}, series = {ANT 2023}, abstract = {Adopting reasonable strategies is challenging but crucial for an intelligent agent with limited resources working in hazardous, unstructured, and dynamic environments to improve the system's utility, decrease the overall cost, and increase mission success probability. This paper proposes a novel hierarchical strategy decomposition approach based on the Bayesian chain rule to separate an intricate policy into several simple sub-policies and organize their relationships as Bayesian strategy networks (BSN). We integrate this approach into the state-of-the-art DRL method – soft actor-critic (SAC) and build the corresponding Bayesian soft actor-critic (BSAC) model by organizing several sub-policies as a joint policy. We compare the proposed BSAC method with the SAC and other state-of-the-art approaches such as TD3, DDPG, and PPO on the standard continuous control benchmarks – Hopper-v2, Walker2d-v2, and Humanoid-v2 – in MuJoCo with the OpenAI Gym environment. The results demonstrate that the promising potential of the BSAC method significantly improves training efficiency.}, keywords = {autonomy, learning}, pubstate = {published}, tppubtype = {conference} } Adopting reasonable strategies is challenging but crucial for an intelligent agent with limited resources working in hazardous, unstructured, and dynamic environments to improve the system's utility, decrease the overall cost, and increase mission success probability. This paper proposes a novel hierarchical strategy decomposition approach based on the Bayesian chain rule to separate an intricate policy into several simple sub-policies and organize their relationships as Bayesian strategy networks (BSN). We integrate this approach into the state-of-the-art DRL method – soft actor-critic (SAC) and build the corresponding Bayesian soft actor-critic (BSAC) model by organizing several sub-policies as a joint policy. We compare the proposed BSAC method with the SAC and other state-of-the-art approaches such as TD3, DDPG, and PPO on the standard continuous control benchmarks – Hopper-v2, Walker2d-v2, and Humanoid-v2 – in MuJoCo with the OpenAI Gym environment. The results demonstrate that the promising potential of the BSAC method significantly improves training efficiency. |
Publications
2026 |
|
| Hybrid Framework for Multi-Robot Target Search in Unknown and Adversarial Environments Conference Forthcoming 2026 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Forthcoming. |
| Imitation-BT: Automating Behavior Tree Generation by Echoing Reinforcement Learning Agents Conference 2026 IEEE International Conference on Robotics & Automation (ICRA), 2026. |
2025 |
|
| Edge Computing and its Application in Robotics: A Survey Journal Article Journal of Sensor and Actuator Networks, 14 (4), 2025. |
| 2025 IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS), 2025. |
2024 |
|
| Bayesian Strategy Networks Based Soft Actor-Critic Learning Journal Article ACM Transactions on Intelligent Systems and Technology, 15 (3), pp. 1–24, 2024. |
| Communication-Efficient Multi-Robot Exploration Using Coverage-biased Distributed Q-Learning Journal Article IEEE Robotics and Automation Letters, 9 (3), pp. 2622 - 2629, 2024. |
| 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024), 2024. |
| Route Planning for Electric Vehicles with Charging Constraints Conference 2024 IEEE 100th Vehicular Technology Conference (VTC2024-Fall), 2024. |
| Bayesian Soft Actor-Critic: A Directed Acyclic Strategy Graph Based Deep Reinforcement Learning Conference 2024 ACM/SIGAPP Symposium on Applied Computing (SAC) , IRMAS Track 2024. |
| PhysicsAssistant: An LLM-Powered Interactive Learning Robot for Physics Lab Investigations Workshop IEEE ICRA 2024 Workshop on Accelerating Discovery in Natural Science Laboratories with AI and Robotics, 2024, (Selected for the Pioneer Award). |
2023 |
|
| A Strategy-Oriented Bayesian Soft Actor-Critic Model Conference Procedia Computer Science, 220 , ANT 2023 Elsevier, 2023. |